|
Kafka |
Scroll |
Kafka is a robust clustered distributed streaming platform used to build real-time streaming replication pipelines that reliably move data between systems or applications using a publish and subscribe architecture.
Customers choose it because they want to do more than simply replicate captured source data into a, dare we say legacy, relational datastore. Some use the stream of kafka messages as the mechanism to identify "events" that trigger subsequent downstream business processes. Others use it to populate a "big data" repository where other tools will be used for analytics or to answer questions that may not even be known at the start of a project.
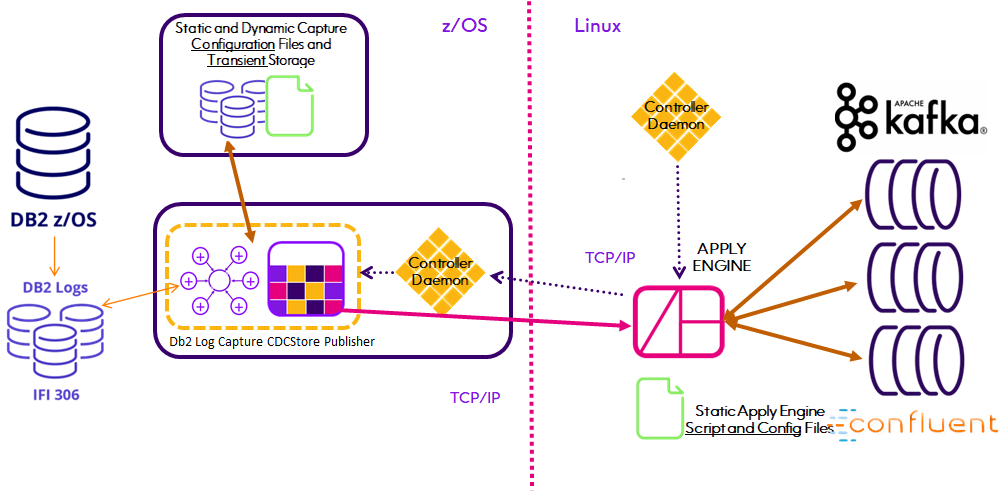
Apply Engine
Utilizing the Engine REPLICATE function, the Apply Engine automatically generates JSON and registration of AVRO schemas.
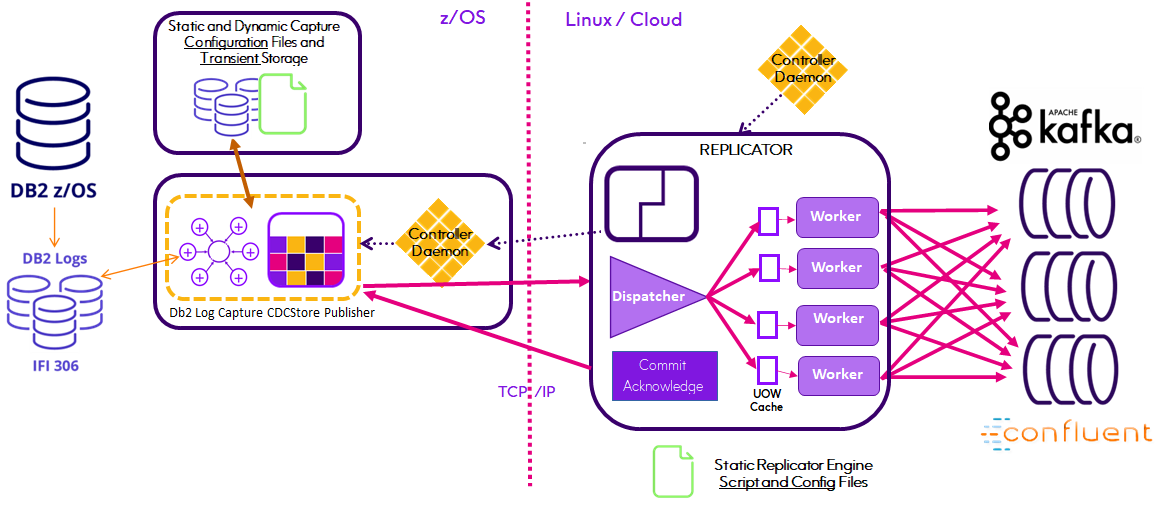
Replicator
The Replicator Engine fully automates the propagation of source schema changes and Kafka message production using AVRO and the Confluent Schema Registry. The Replicator also supports parallel processing of the replication workload through multiple Producer threads with the number of threads or workers specified at run-time. This means that Connect CDC SQData becomes a utility function within the enterprise architecture, reacting to Relational schema changes without interruption and without maintenance of the Connect CDC SQData Kafka producer configuration running in your Linux environment.
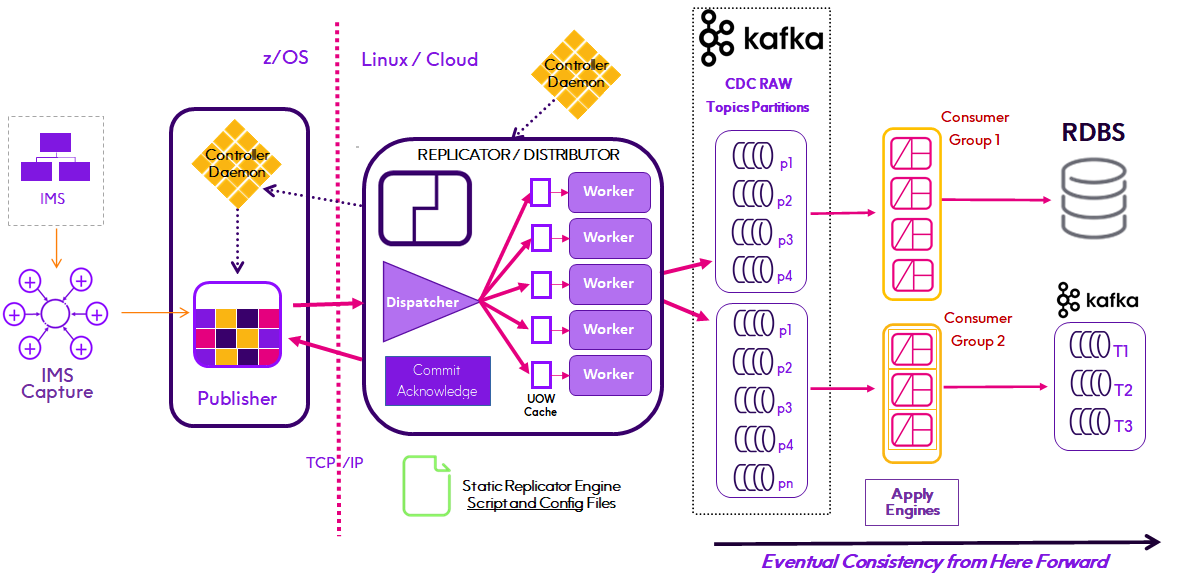
Replicator Distributor
When operating as a Parallel Processing Distributor IMS CDCRAW records stream to Kafka topics partitioned by Root Key for processing by Apply Engines configured as Kafka Consumer groups. Splitting the stream of published data to be consumed by Apply Engines that write (Apply) that data to target datastores of any type.