|
Replication Pipelines |
Scroll |
The Pipeline refers to the flow of data from Source to Target platform and is essentially identical regardless of the platform operating systems and type of Source and Target Datastore.
Apply Engine and Replicator Engines
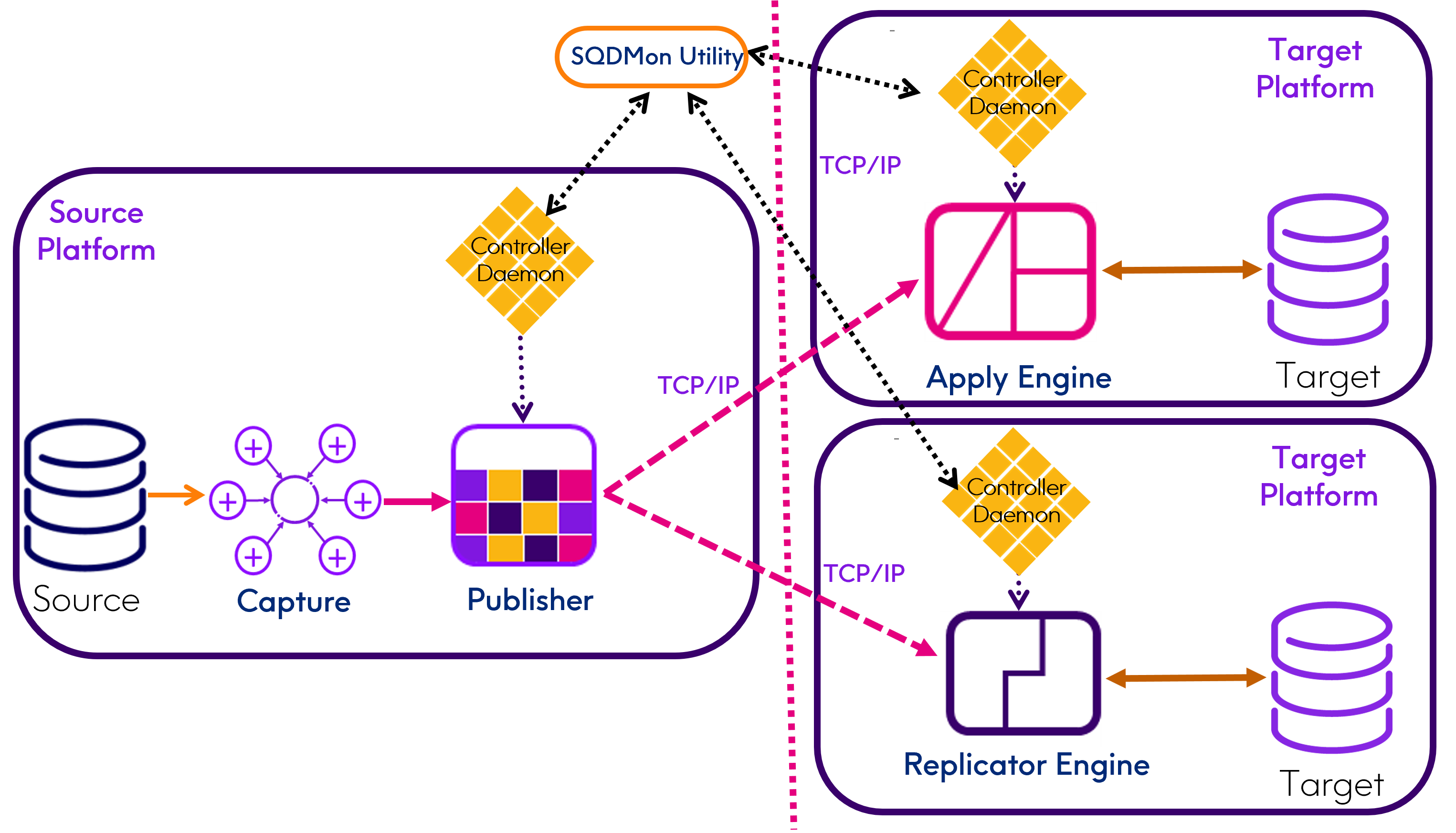
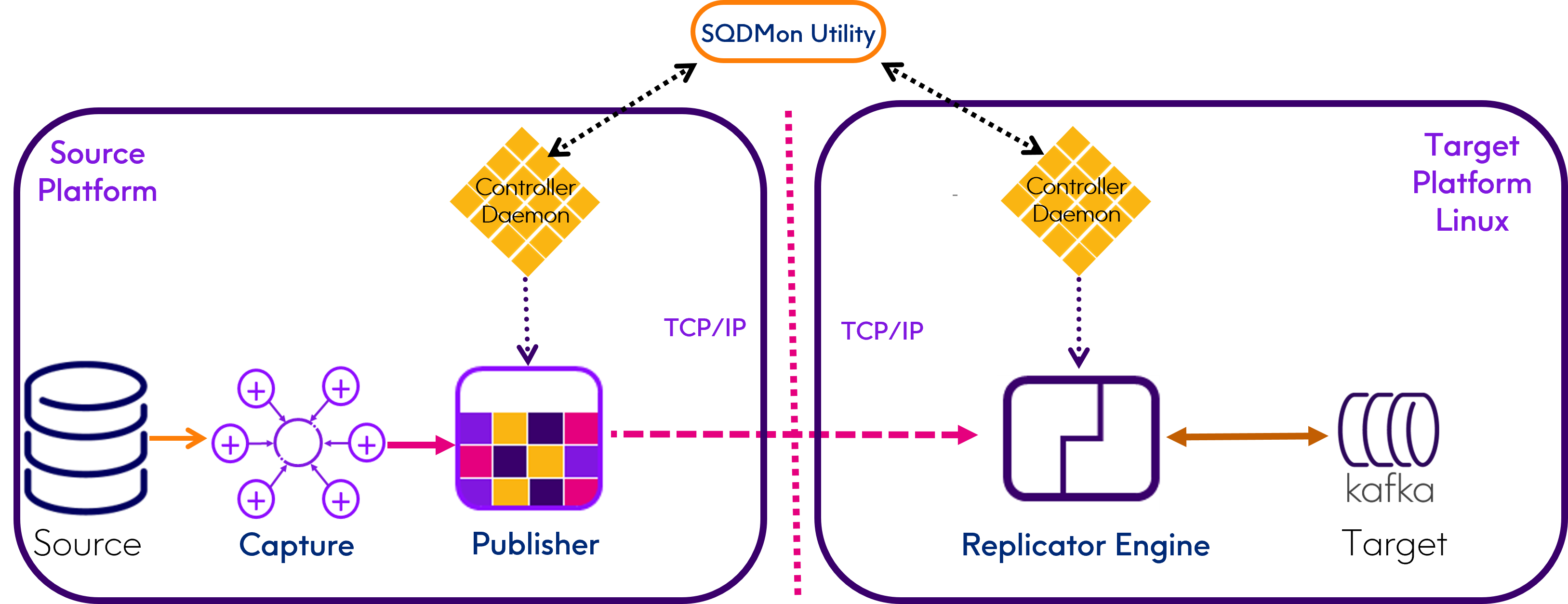
While there are some platform specific options the picture remains the same Publish and Subscribe model sequence of Capture, Publisher, Subscribing Apply or Replicator Engine components. There are really only two other variations.
1.Kafka (and Kafka compatible) Targets and HDFS Targets require the platform running the Engine to be Linux as it is the only operating system supported by the Open Source librdkafka C Language API.
2.When a Replicator Engine operating in Parallel IMS Distributor mode writes to Kafka with downstream Apply Engine Kafka consumers both the Replicator and the Apply Engines must run on Linux due to the requirement for librdkafka.
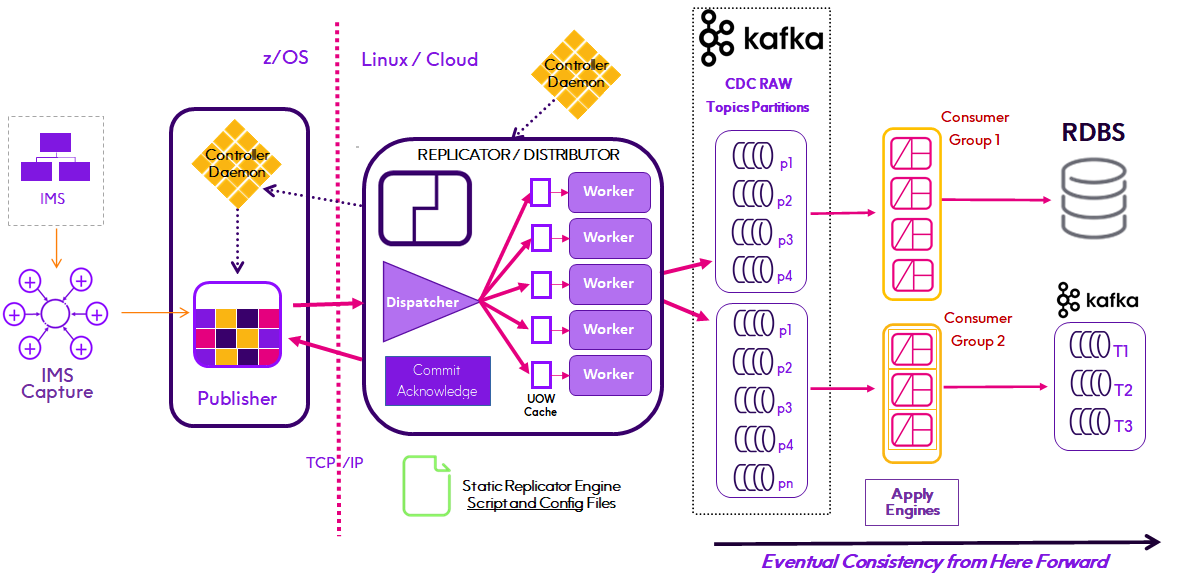
Replicator Engine
Replicator Engine as IMS Parallel Distributor