|
Kafka Quickstart |
Scroll |
Kafka is a robust clustered distributed streaming platform used to build real-time streaming data pipelines that reliably move data between systems or applications using a publish and subscribe architecture.
Customers choose it because they want to do more than simply replicate captured source data into a, dare we say legacy, relational datastore. Some use the stream of kafka messages as the mechanism to identify "events" that trigger subsequent downstream business processes. Others use it to populate a "big data" repository where other tools will be used for analytics or to answer questions that may not even be known at the start of a project.
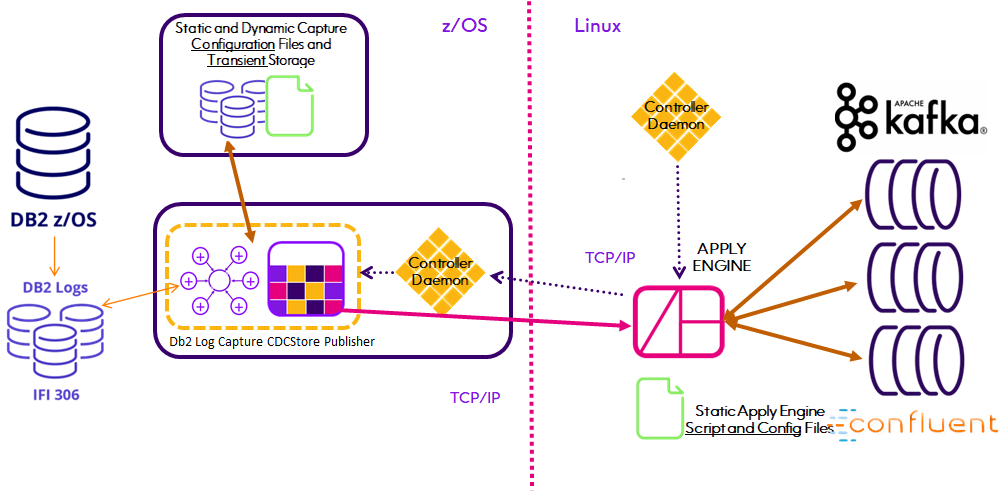
This Quickstart illustrates two methods provided by Connect CDC SQData to replicate changes in virtually any source datastore into Kafka. The first utilizes our time tested high performance Capture agents and Apply Engine technology while the second introduces a new capability that eliminates maintenance of the Apply Engine when table structures are changed in Relational source datastores, beginning with Db2 z/OS.
Both methods simplify the creation, configuration and execution of the replication process by utilizing an Engine that Applies to Kafka Topics. Connect CDC SQData treats Kafka as a simple Target Datastore for information captured by any of Connect CDC SQData's capture agents. Precisely's Connect CDC SQData product architecture provides for the direct point-to-point (Source to Target) transfer of captured data without the use of any sort of staging area. When properly configured, captured data does not require or even land on any intermediate storage device before being loaded into the target Kafka Topic.
While Connect CDC SQData can be used to implement a solution that customizes the data written to Kafka, we and the industry don't recommend it. There are several reasons but the most obvious are the ongoing maintenance requirements. Streaming data to Kafka is fundamentally different from replicating data, for example from mainframe Db2 to Oracle on Linux.
In a Db2 to Oracle use case, it is understood that both source and target table schemas will change and they may never be identical or even share identical column names. DBA maintenance of the Db2 schemas will be scheduled to minimize disruption of source applications and the downstream Oracle applications will have to decide if and how to absorb those changes. Oracle DBA's will have to coordinate changes to their schemas with the Db2 DBA's and the Oracle application developers. Consequently the Connect CDC SQData Apply Engine in the middle will need to have it's source Descriptions updated and possibly the Oracle target table Descriptions updated as well. Changes to mapping Procedures may also have to be changed. Solid configuration management procedures are required to fully implement these changes.
Implementing a Kafka architecture changes all that. Kafka data consumers read the JSON formatted data in a Kafka message that also contains the schemas describing that data. The biggest issue with this technique however are the JSON schemas included in the payload of every single Kafka message produced and consumed. That problem is solved by the AVRO data serialization system which separates the data from the schema. Data is read by the consumer using the schema that describes the data at the time it was written by a producer. This of course assumes that the tools and languages used by the producer and consumer are AVRO "aware". With Connect CDC SQData Version 4, we have embraced Confluent's Schema Registry for managing the schema versions of AVRO formatted Kafka messages through the automatic registration of Kafka topic schemas.
Apply engines that utilize the REPLICATE function, for DB2 as well as IMS and VSAM source data will still require manual intervention to replace the source DESCRIPTION parts that correspond to altered schemas or changed "copybooks". Once that has been accomplished however the Apply Engine need only be Parsed and Started and the registration of the updated AVRO schemas will be performed automatically. Even Version 4 Apply Engines that have "customized" target DESCRIPTIONS and mapping PROCEDURES will benefit because the Target DESCRIPTIONS used to create the AVRO schemas will be automatically validated and registered, if necessary, when the Engine is Started.
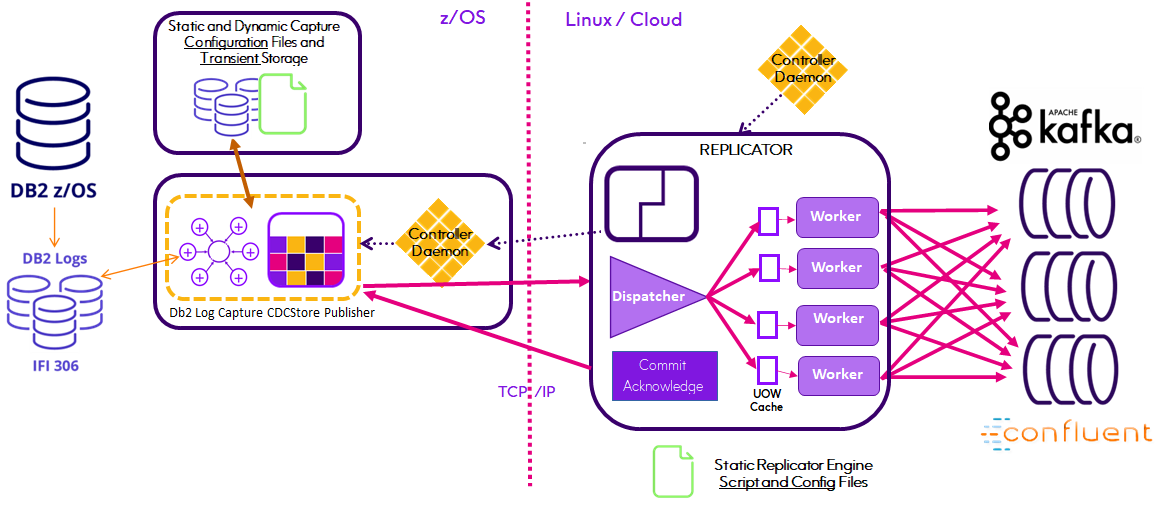
Finally, Connect CDC SQData Version 4 also introduces our revolutionary Replicator Engine for relational source databases beginning with Db2 12 z/OS. The Replicator Engine fully automates the propagation of source schema changes and Kafka message production using AVRO and the Confluent Schema Registry. The Replicator also supports parallel processing of the replication workload through multiple Producer threads with the number of threads or workers specified at run-time. This means that Connect CDC SQData becomes a utility function within the enterprise architecture, reacting to Relational schema changes without interruption and without maintenance of the Connect CDC SQData Kafka producer configuration running in your Linux environment.
Notes:
1.Kafka is only supported on the Linux OS platform. Connect CDC SQData's distributed architecture however enables data captured on virtually any platform and from most database management systems to become a Kafka topic.
2.Messages are written to Kafka asynchronously which means the Apply and Replicator Engines do not wait for Kafka to acknowledge receipt before writing another message. A delay in acknowledgment by Kafka may be due to replication occurring within Kafka itself (particularly with Kafka ACK mode 2). The Replicator does ensure that Units-of-Work (UOWs) are acknowledged to the Publisher in sequence preventing loss of captured data.
3.The Connect CDC SQData warning message SQDUR10I Max In-flight UOWS reached: <n> indicates a potential Kafka problem (slowdown or outage). The default maximum number of in-flight UOW's is 100 but can be controlled by the --max-uow=<nnn> parameter.
To learn more, Connect CDC SQData recommends both Apache's AVRO documentation and Confluent's Schema Registry Tutorial available on web browsers everywhere.