|
Replicator Engine |
Scroll |
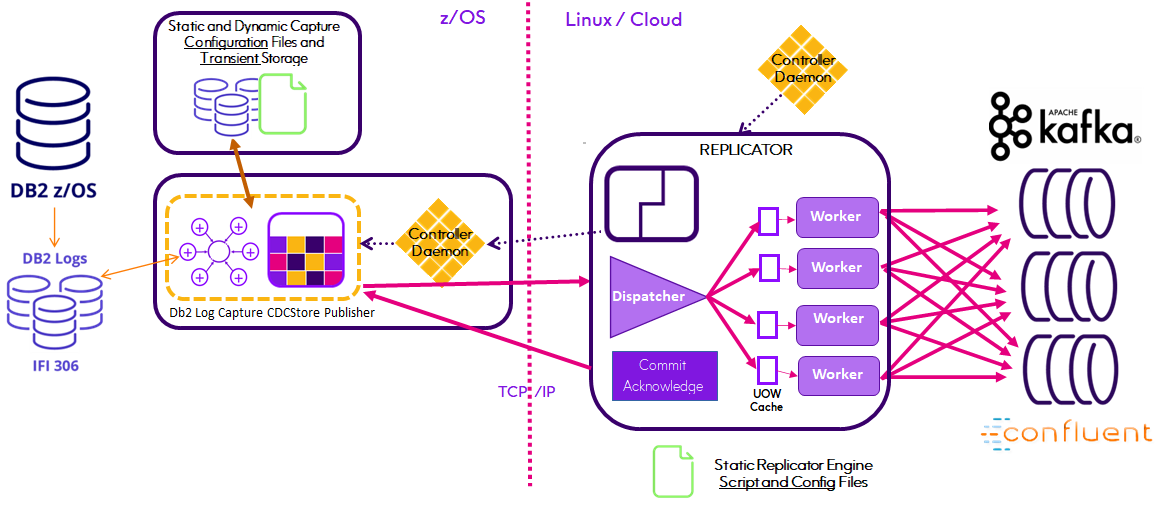
The Replicator Engine is controlled by a configuration file that merely identifies source and target datastores. It operates in two modes, as a high performance relational source Replicator and as a Distributor for parallel processing of IMS source data .
In Relational Replication mode, it automatically generates industry standard JSON or AVRO formatted data including a seamless interface with Confluent's Schema Registry to further simplify administration while boosting performance.
 When operating as a Parallel Processing Distributor IMS CDCRAW records stream to Kafka topics partitioned by Root Key for processing by Apply Engines configured as Kafka Consumer groups. Splitting the stream of published data to be consumed by Apply Engines that write (Apply) that data to target datastores of any type.
When operating as a Parallel Processing Distributor IMS CDCRAW records stream to Kafka topics partitioned by Root Key for processing by Apply Engines configured as Kafka Consumer groups. Splitting the stream of published data to be consumed by Apply Engines that write (Apply) that data to target datastores of any type.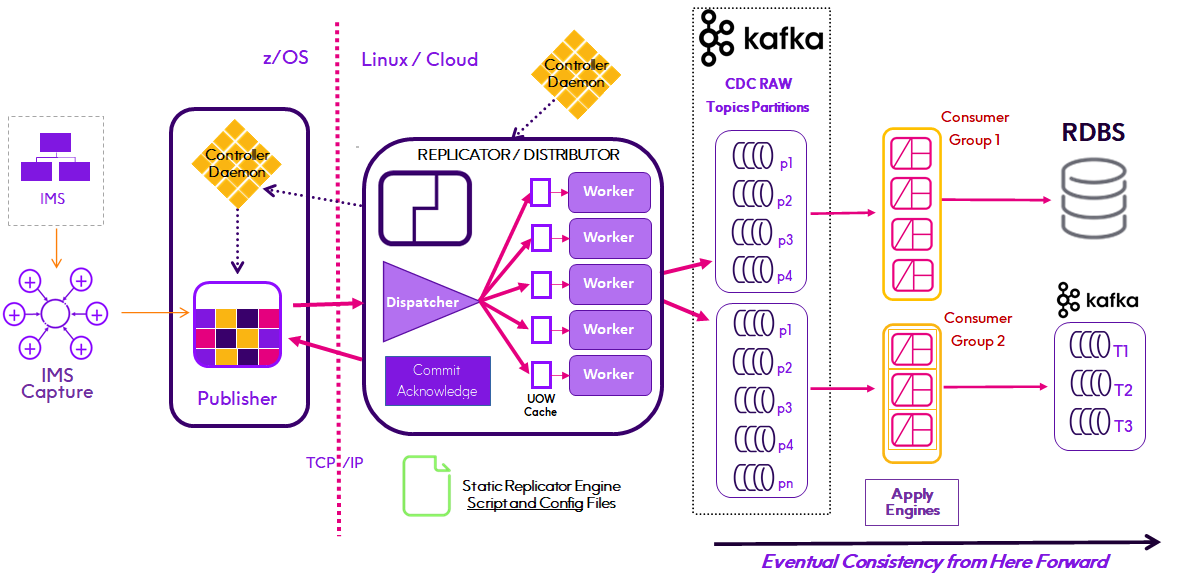
The Kafka Quickstart provides step by step guides to the installation, configuration, testing and operation of both the Apply and Replicator Engine components for Kafka.
The following sections provide a detail level Reference to the development and operation of Replicator Engines.
•Replicator Engine Features and Functions An overview of Replicator Engine concepts including cross-platform operation, data propagation and parallel workload distribution.
•Replicator Script Development Preparation and recommended development steps and the structure and syntax of the Replication script.
•Replicator Engine Execution Describes how the Replicator Engine is initiated both at the command line and under the sqdaemon.
•Use Case Scenarios Describe commonly encountered implementations of the Replicator with Kafka and Hadoop (HDFS).
•Replicator Engine Troubleshooting Provides assistance for diagnosing common problems encountered during the operation of the Replicator Engine.